Synth Lab
Don't just read research—watch it think. AI agent powered architect that transforms the static text of multiple arXiv papers into "living" structural models. Synth Lab is a multimodal "Live Lab Notebook" that doesn't just explain research papers; it architecturally reconstructs them. As the agent analysis methodology of one or more arXiv papers, it simultaneously "draws" the logic in real-time using interleaved D3.js and Mermaid.js diagrams.
Demo
Synth Lab — live walkthrough
Screenshots


.png)
.png)
.png)
.png)
.png)
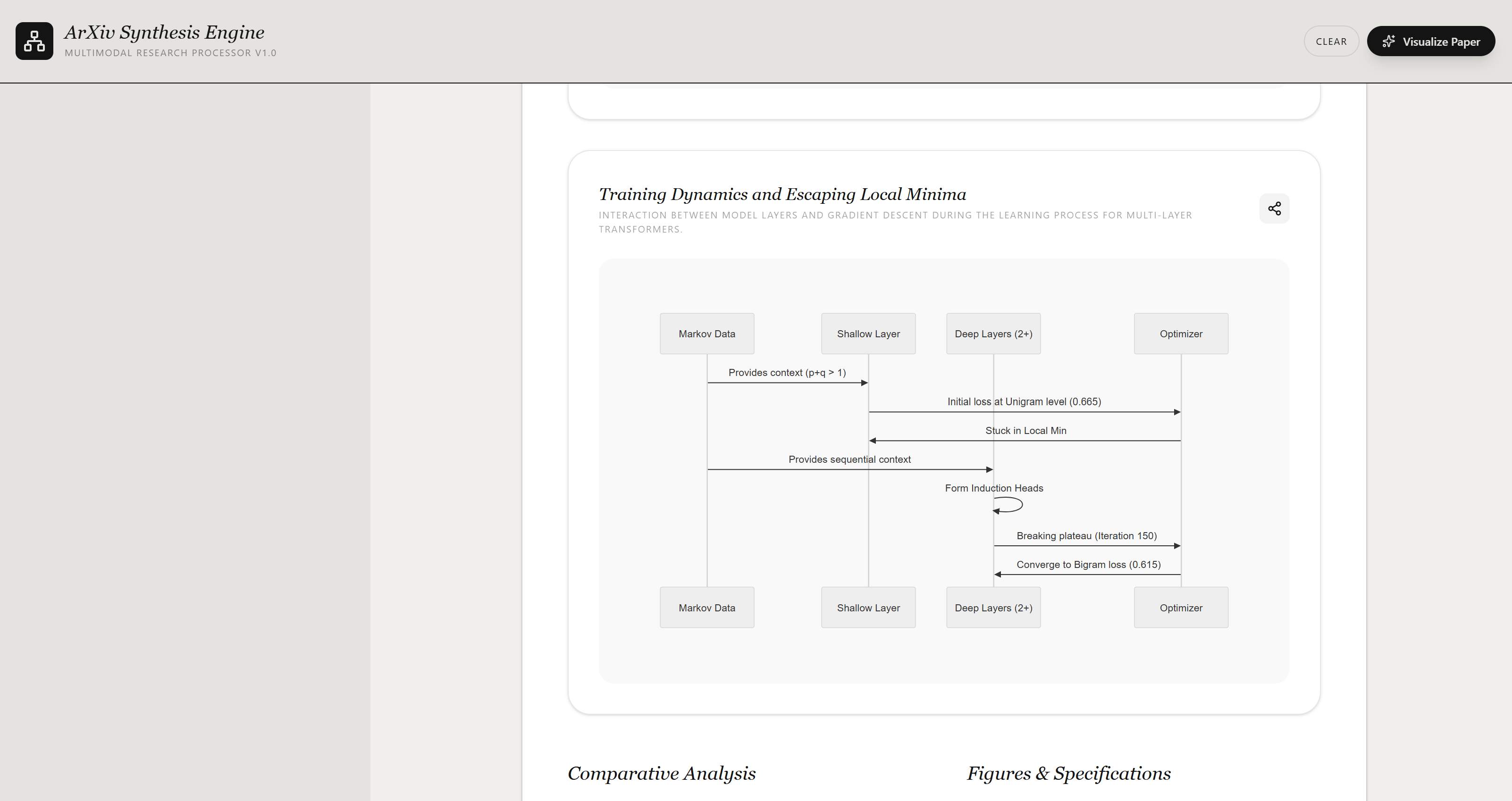
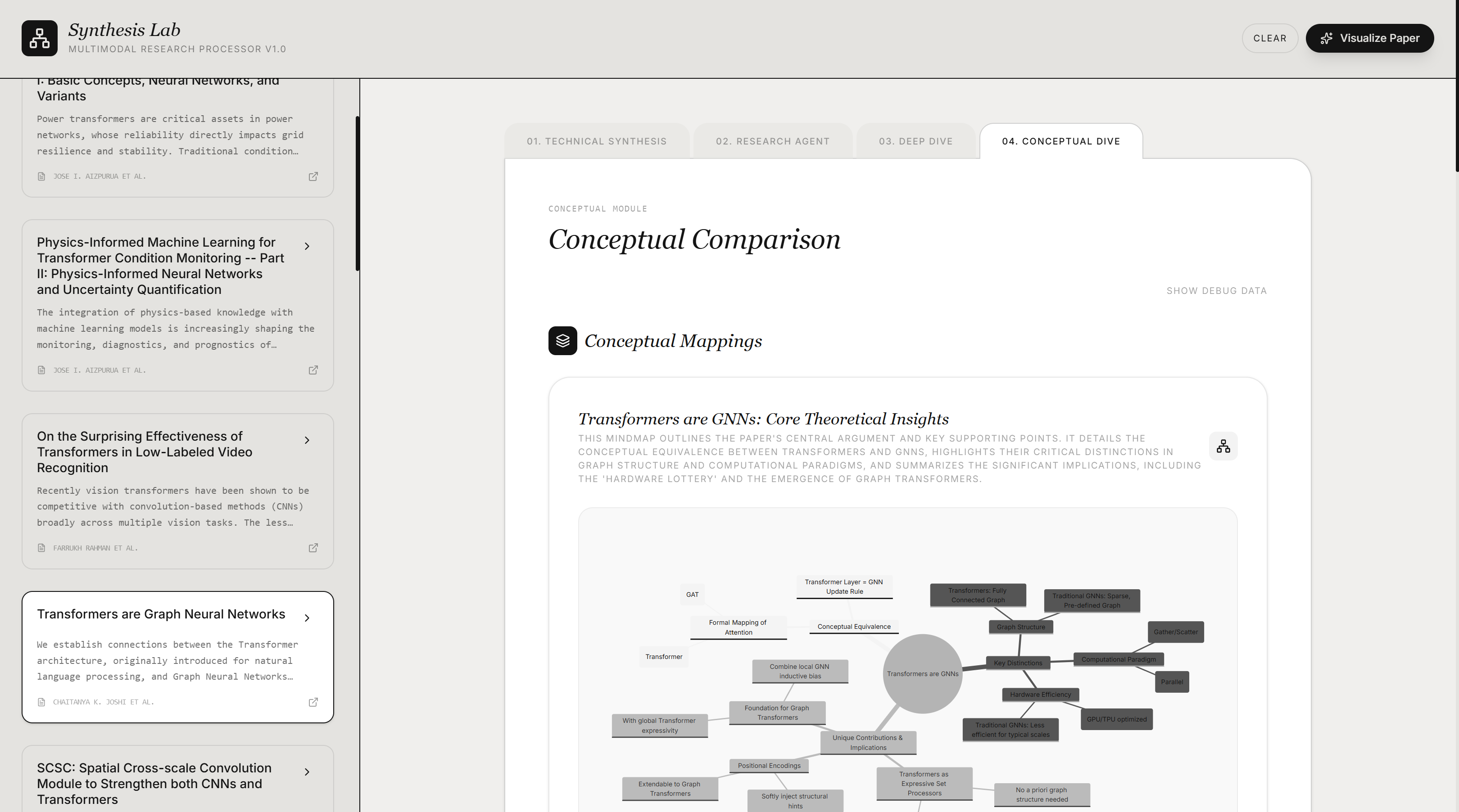
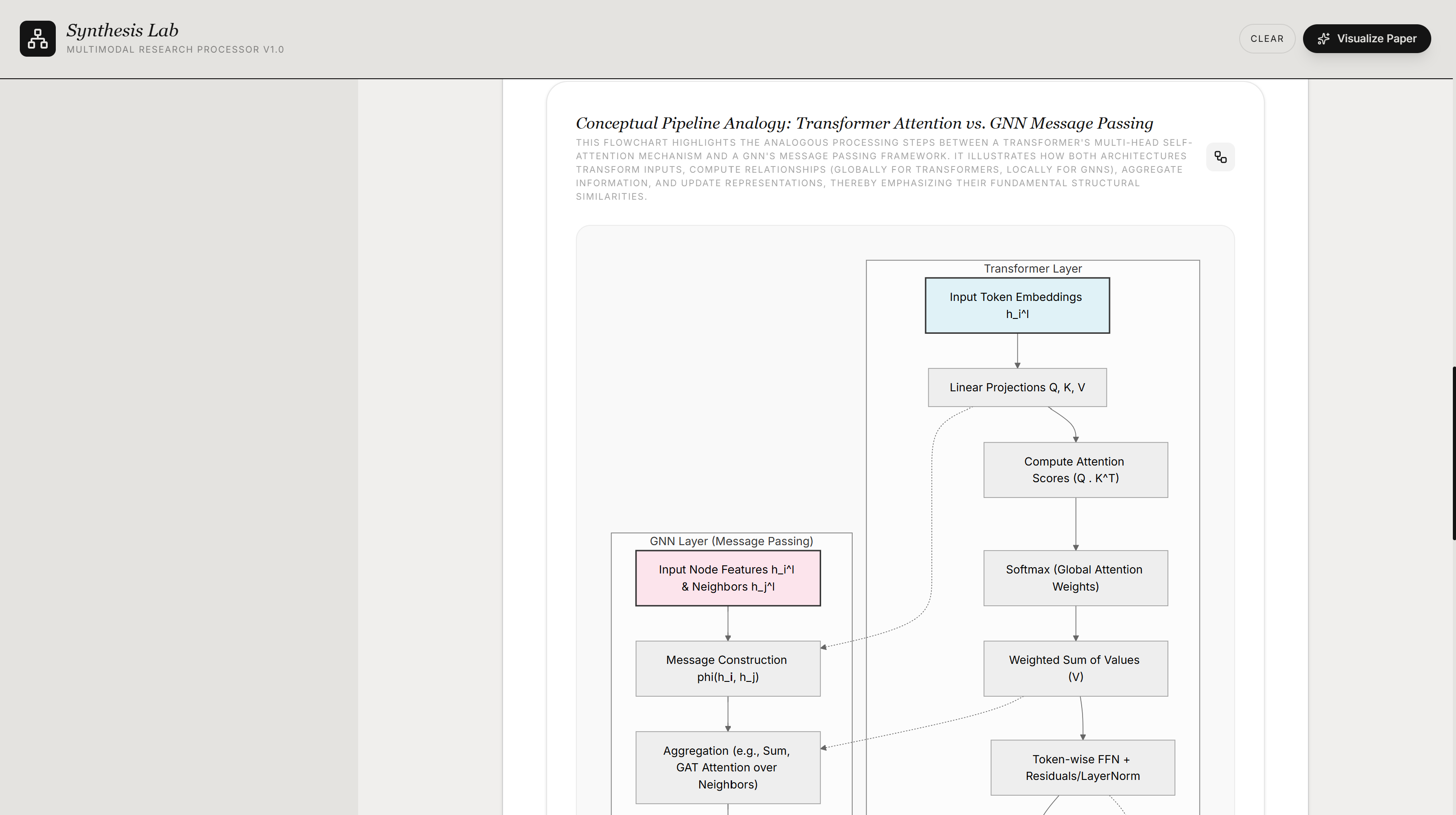
Problem Statement
The Problem
Academic research papers on arXiv are dense, static documents. Most AI summaries and outlines are just walls of text that lose the complex architecture of a research paper. Readers must manually trace through complex architectures, methodology flows, and hierarchical relationships buried in text and raw figures — a cognitive bottleneck that slows down understanding and knowledge synthesis, especially in fast-moving fields like ML & AI, Markets, and Drug Discovery.
There was no automated way to instantly convert a paper's structural logic into an interactive, navigable diagram — forcing researchers and engineers to spend hours building mental models that an AI could generate in seconds.
Solution
The Architecture
Built under a 10-day competition deadline, the backend was intentionally kept thin. The Express server acts as a secure gateway between the frontend and external services, keeping the Gemini API key off the client, proxying arXiv searches and PDF fetches to avoid browser CORS issues, and shaping prompts before sending them to Gemini. The frontend owns everything else: user workflow, session state, and all rendering decisions.
The core data flow is: arXiv search query -> backend proxy normalizes the Atom feed into paper objects -> selected papers sent to Gemini for analysis -> structured JSON returned -> React renders the result across four tabs. Those four tabs are not four separate products. They are four projections of the same underlying paper analysis pipeline, each giving the user a different lens over the same research corpus.
The backend makes three distinct Gemini calls. Conceptual Dive runs a two-pass pipeline: the first call analyzes and compares the paper contents, and the second converts that analysis into structured Mermaid diagram JSON. The third call is separate, handling audio narration generated for the Research Agent tab via Gemini's TTS capability. The application is deployed on Google Cloud Run via Docker, with Vite middleware handling development serving and static file serving in production.
Known Limitations
Known Limitations
Synth Lab shipped as a competition entry. Using it in production revealed four specific architectural gaps worth being honest about.
- Conceptual Dive is slow. Because Gemini analyzes paper content and generates diagrams in the same sequential pipeline, response times grow significantly with multiple papers. The fix is splitting the two passes: generating and caching the raw analysis first, then generating diagrams from that stored output in a separate step so repeated requests do not re-run expensive inference.
- PDF fetches are never cached. Every request re-downloads the same PDFs from arXiv, adding unnecessary latency and cost at scale. A persistent storage layer in v2 addresses this by storing fetched PDFs on first access and serving them locally on subsequent requests.
- Mermaid diagram generation breaks on complex papers. LLM-generated Mermaid syntax is fragile and long or dense papers produce diagrams that exceed what the renderer handles gracefully. There is no validation or retry logic when syntax errors occur and the error surfaces directly to the user with no fallback. A structured output layer with schema enforcement and fallback parsing would fix this.
- The streaming UI is simulated. The animated output feels like token-by-token generation but is actually batched. The backend returns a full Gemini response and the client incrementally renders it. It works, but it is a UI approximation of a real capability.
These four limitations are the direct motivation for v2.
What's Next
What's Next
The known limitations in v1 are the roadmap for v2, not an afterthought.
The two-pass Conceptual Dive pipeline needs to be split into stages. Raw analysis would be generated and stored first, then diagrams generated from that cached output separately. That eliminates redundant inference on repeated requests and makes the pipeline easier to debug.
PDF fetches need a persistent caching layer. The current architecture re-downloads the same files on every request. Storing fetched PDFs on first access and serving them locally afterward would significantly reduce latency and external API dependency.
Mermaid generation needs structured output validation and retry logic so syntax errors do not surface raw to the user. Schema enforcement on the Gemini response, with a fallback rendering path, would make diagram generation reliable on complex papers.
Real server-sent event streaming from Gemini through the backend would replace the current simulated streaming UI. The capability exists in Gemini's API and the frontend is already structured to handle incremental output.
Finally, a persistent database would let users save diagrams, searches, and analyses and return to them across sessions, which is the feature gap that matters most for actual research workflows.
Sponsors